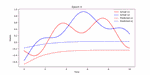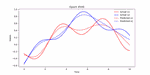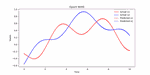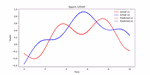
This repository is dedicated to advancing Automatic Speech Recognition (ASR) for the Bengali language, leveraging state-of-the-art machine learning models such as wav2vec 2.0, T5, ARPA, BERT, and BART. This project is part of an experiment to understand and improve ASR performance in processing and recognizing Bengali speech, aiming to create more accurate and efficient ASR systems for Bengali, the seventh most spoken language in the world.